
Why local AI is more important than ever (but not useful yet)
Frontier models like Claude / Codex are extraordinary, but on-device alternatives matter for privacy and cost, and will matter even more in the near future.

TL;DR
My Core argument: Local AI is great for narrow tasks and privacy, but frontier models still dominate agentic and complex work; hybrid architecture is the practical path if you want speed, accuracy and privacy at zero cost.
Hardware gap: The average user (16–32GB RAM) is far from running “useful” local models, and frontier capability sits effectively off the charts on data‑center hardware.
Why I care: I love Claude & Codex, but rising monetization pressure on companies and privacy concerns make local options strategically important for both personal and professional workflows.
Reality check: Local models work for narrow and small-scale tasks such structured extraction and tagging, but fall apart on agentic coding and complex reasoning (and vibecoding of course).
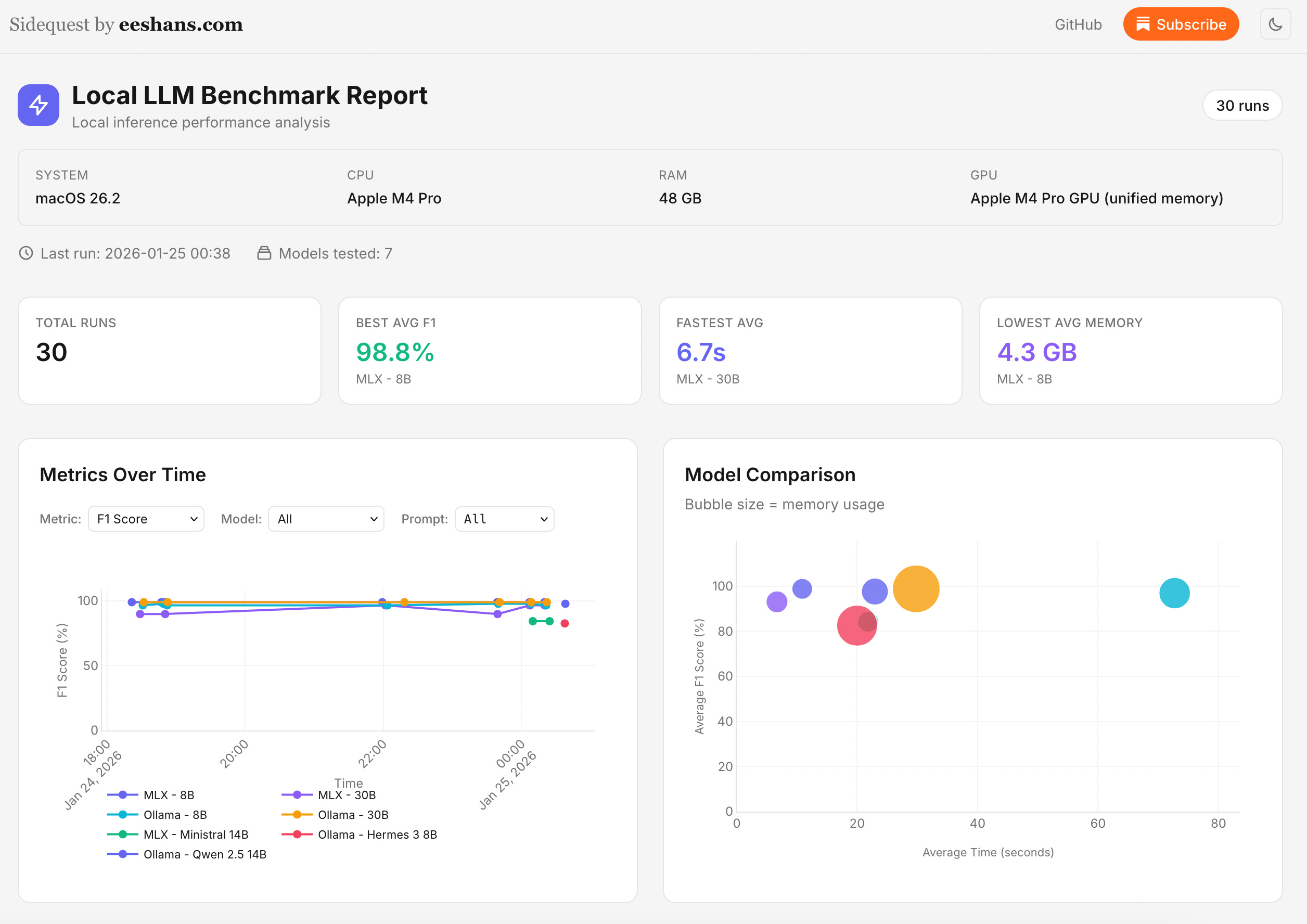
Reframe + takeaway: The right design is a hybrid of deterministic + LLM approaches. Finding the balance between speed & accuracy will take time. I built and open‑sourced a little benchmark runner so I can keep tabs on the tradeoffs as new models are released. View Report | Source
The hardware gap for useful local AI
Discerning causation from correlation is part of my daily job, so I think a lot about selection bias whenever I make broad claims. I did some very rough research on the “average” LLM user’s hardware (specifically RAM, since that’s the main bottleneck for local inference), and tried to visualize the gap between consumer RAM distribution and what counts as a practically useful local model. The claims you see online or in the news rarely represent the average user; they usually reflect companies with effectively unlimited hardware or enthusiasts with high-end setups.
For data, I used Steam’s Hardware Survey (December 2025), which reports aggregated buckets for RAM, VRAM, and CPU. This is a gamer sample, so it’s already more powerful than the general population, meaning any conclusions here are conservative. The survey shows about half of users have 16GB of RAM or less, and nearly 92% have 32GB or less. My 48GB MacBook puts me in roughly the top 7% of that distribution, and enthusiast groups like r/LocalLLaMA often run >128GB RAM on their custom rigs.
Frontier models like Claude and GPT‑5‑class are served on multi‑GPU data‑center nodes with High Bandwidth Memory (HBM), often hundreds of GB per node and scaled across nodes. This chart only shows consumer RAM, so it’s safe to say the frontier point is effectively off the chart. There’s a reason why companies are investing enormous sums into data‑center projects like Stargate.
Source: Steam Hardware Survey (December 2025). Model RAM requirements based on typical configurations for Llama/Qwen models.
As the chart shows, the average RAM buckets sit between 16–32GB. That’s enough to run a 7–8B model like Qwen3‑8B, which is quite capable for structured extraction based on my own tests (see benchmark below). At 128GB RAM, where many r/LocalLLaMA enthusiasts start, you can run more practical 70–80B models like Qwen3‑Next‑80B‑A3B‑Instruct. For frontier models like Claude 4.5+ and ChatGPT 5+, parameter counts aren’t public, but they’re likely very large (possibly >1T). Running these models requires enormous memory and compute.
Bottom line: for anything truly “useful” in local AI, the average person is far from being able to use those models the same way they use Claude or ChatGPT today.
Why I Care (and Why You Might Too)
I’m not experimenting with local models to be contrarian or to build $22K rigs. Frontier models are cutting edge, and I happily pay for them. Claude and Codex are core to my personal workflows. I care about local AI for two reasons: (1) monetization pressure is rising, and (2) privacy matters for sensitive data.
OpenAI plans to test ads for free ChatGPT users, with sponsored results placed inside chats. (Our approach to advertising and expanding access to ChatGPT | OpenAI)
Google is rolling out “Personal Intelligence” features that let Gemini and Search AI Mode pull from Gmail and Photos to personalize results. (Personal Intelligence: Connecting Gemini to Google apps)
The premium tiers are already expensive: ChatGPT Pro is listed at $200/month, and Claude Max ranges from $100 to $200/month. (OpenAI pricing, Pricing | Claude). Compared to their API pricing, they’re a better deal, but I wouldn’t be surprised if prices shift upward over time.
API pricing for frontier models is usage‑based and can add up fast at scale. (OpenAI API pricing, Pricing - Claude API Docs)
None of this diminishes how impressive these systems are. Frontier models are still the best tools we have for complex work; the point is incentive alignment, not villainy.
For certain use cases, especially anything touching personal data, I want a credible on‑device option that doesn’t require sending my notes, journals, or private documents to the cloud, where you have limited control beyond policy trust and contracts (and companies can pivot any time).

The Reality: Where Local LLMs Work and Where They Don’t
So with incentives shifting and for my own curiosity, I wanted to test where local LLMs actually hold up.
Where local models deliver:
Specialized, well-defined tasks (still at a relatively small scale)
Structured extraction, classification, and tagging
Text transformations and templated outputs
Low-stakes analysis on sensitive or private data
Where local models fall apart:
Agentic coding and complex reasoning
Multi-step workflows that require tool use and memory
High-stakes workflows where mistakes are expensive
Right now I have a solid Claude/Codex + Obsidian setup for my personal notes and productivity system (using the brilliant Obsidian ACP plugin). But I know this is the worst option from a privacy perspective. So I’ve been working on building a hybrid local-only AI-powered notes system. I can’t just point a local 7B or even 30B model at my notes and expect anything close to the value I get from Claude or Codex today. This will require a very different approach if I want to eventually hit the trifecta of fast, cheap (free), and private (on-device).
To keep tabs on how local models are progressing, I built a small benchmark runner to test speed, accuracy and memory usage for structured signal extraction on my laptop’a hardware. Currently it’s only testing a single use case, but I’ll expand this to a much more exhaustive benchmark in the future. The benchmark runner outputs an interactive report. It shows model comparisons, system specs, and speed, accuracy, and memory trade-offs across MLX and Ollama. If you have an Apple silicon mac, you will like MLX. View Report | View Source
The Reframe: Hybrid Architecture Is the Practical Path
The question isn’t “Can a local model replace Claude or Codex?” For complex work today, the honest answer is no. The question is: How do you architect systems that use local AI efficiently and are good enough?
Most production workflows involving natural language are not pure LLM calls. Most companies cannot afford to do everything with Anthropic or OpenAI token pricing, and individuals will burn through money quickly. The practical approach is hybrid ML, NLP, and RAG:
Deterministic code for predictable tasks like preprocessing, rules, and validation
Embeddings + retrieval for fast, reliable context access
Local extraction for PII-heavy tasks like labeling, feature tagging, schema inference, and summarization
Frontier models for the last mile such as synthesis, experiment design, ambiguous tradeoffs, and user-facing reasoning
Two concrete examples:
Conversational layer on a recommender: the LLM explains why an item was suggested using model outputs and metadata.
Experiment results review: the LLM summarizes A/B results and pulls key metrics from structured tables.
The local LLM becomes one component in a larger pipeline, not the whole system.
I’m building something like this for my own personal workflows. An AI notes system with structured extraction + embeddings + lightweight classification, with LLMs only when I need interactive reasoning. The irony is I’m using frontier models to build it, otherwise it’ll be impossible for me to do in my busy time.
Takeaways
Don’t expect local models to replace frontier models for agentic coding and complex workflows any time soon.
Experiment using local models for narrow, private tasks where cost or data sensitivity matters. See if they’re “good enough” even if they’re not perfect.
If you’re on a Mac with < 32GB RAM, try MLX. The speed gains are real.
If you’re in data science, start designing hybrid pipelines now. You’ll be ready as local capability improves.
If you’re running any local or hybrid workflows (personal or professional), I’d love to hear what’s working for you.